| 文件名 | dataprocess_outlier.xlsx |
|---|---|
| 数据用途 | 异常值处理案例数据 |
| 变量说明 | height_cm、weight_kg、income_monthly 和 score 为待检查变量,group 可用于分组观察。 |
完整案例
1. 背景
建模前发现某些变量存在明显超出业务范围或统计范围的数值,需要判断是否设为空值或填补。
2. 理论与公式
异常值处理需要先识别极端值,再决定保留、设为空值、填补或缩尾,目标是降低错误或极端观测对结论的扭曲。
Z 分数
绝对 Z 分数过大时可能为异常值。
IQR 规则
箱线图常用异常值判定规则。
均值填补
用正常样本均值替换被判定的异常值。
3. 数据结构
height_cm、weight_kg、income_monthly 和 score 为待检查变量,group 可用于分组观察。
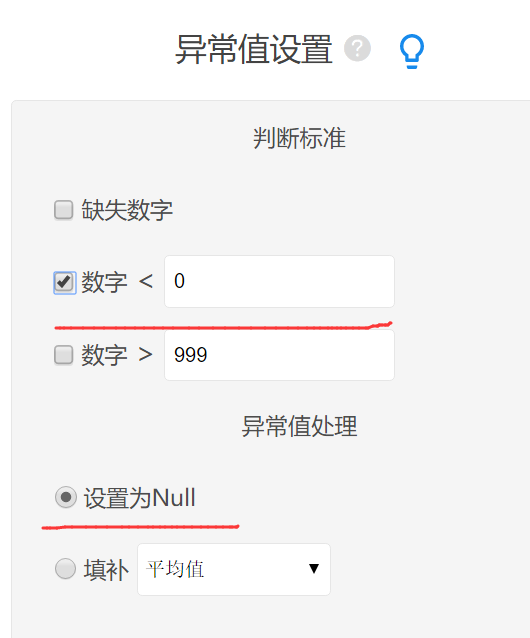
4. 操作步骤与截图
- 上传案例数据
- 先用描述探索或箱线图定位异常范围
- 进入异常值处理
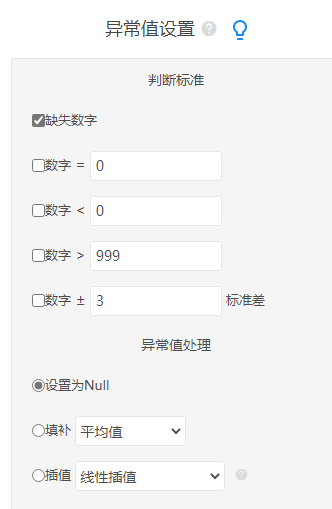
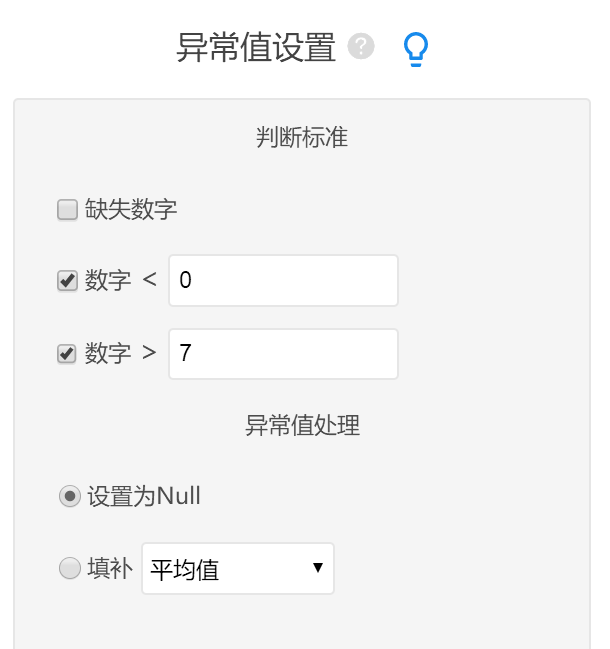
- 设置小于、大于或标准差规则
- 选择设为空值、均值填补或中位数填补
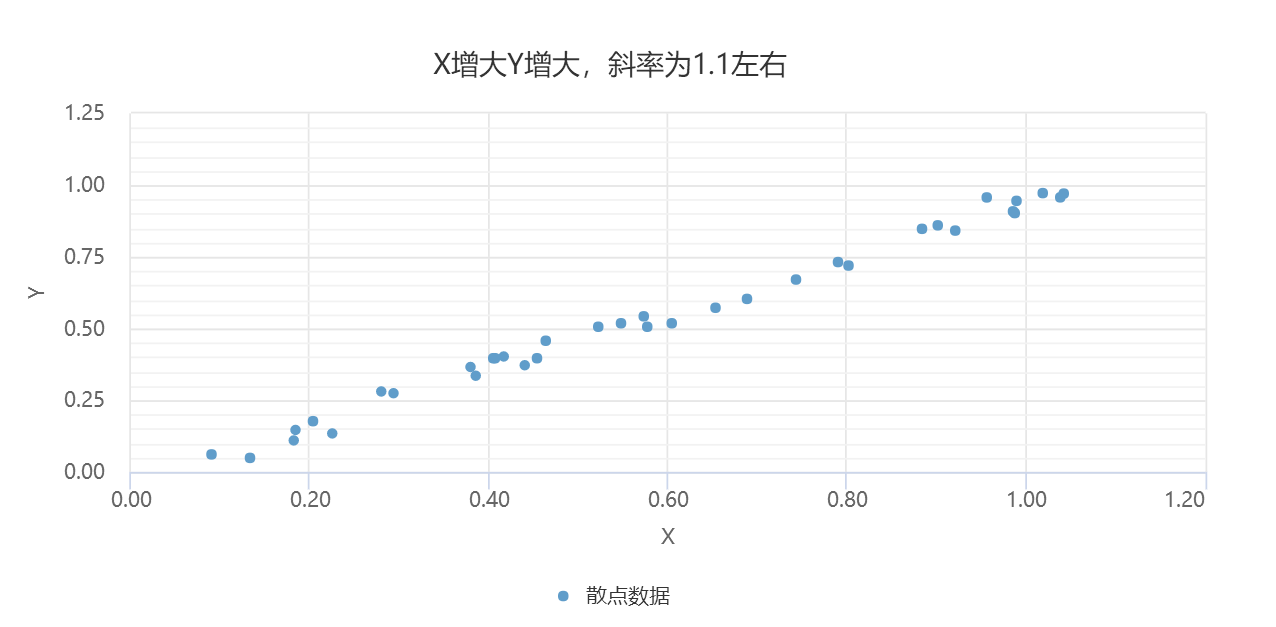
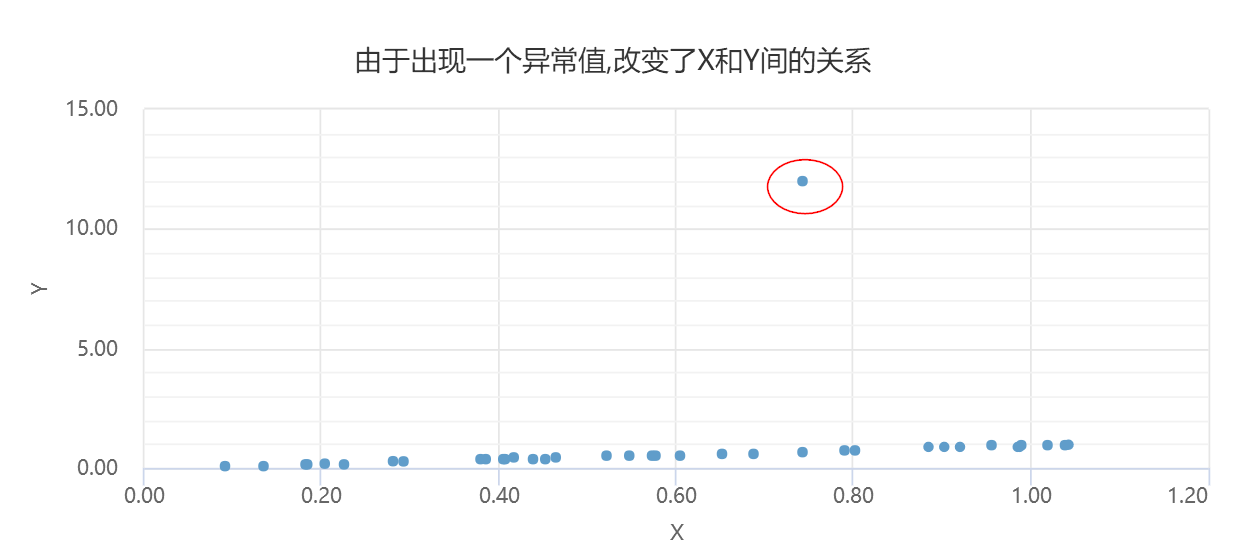
5. 结果表格与核验
| 变量 | 处理前最大值 | 规则 | 处理方式 | 处理后最大值 |
|---|---|---|---|---|
| height_cm | 226 | >210 | 设为空值 | 188 |
| income_monthly | 180000 | 大于3个标准差 | 中位数填补 | 32000 |
| score | -2 | <0 | 设为空值 | 98 |
处理前后应保留口径说明,避免结果不可追溯。
重点比较处理前后的最小值、最大值、均值和样本量,确认异常处理没有误伤正常样本。
6. 辅助截图
7. 文字分析
异常值处理后,极端数值对均值、相关和回归系数的扭曲会降低,结果解释更稳健。
8. 剖析提醒
异常值不一定都是错误数据。处理前应结合业务含义、录入规则和原始记录判断。