| 文件名 | dataprocess_coding.xlsx |
|---|---|
| 数据用途 | 数据编码案例数据 |
| 变量说明 | education 为 1 到 5 的学历编码,reverse_item 为 1 到 5 的反向题,age 可按区间重新分组。 |
完整案例
1. 背景
研究者希望把学历五分类合并为三组,并把反向量表题处理成与其他题方向一致。
2. 理论与公式
数据编码会改变变量取值,常见用途包括合并类别、反向计分和按区间生成分组。
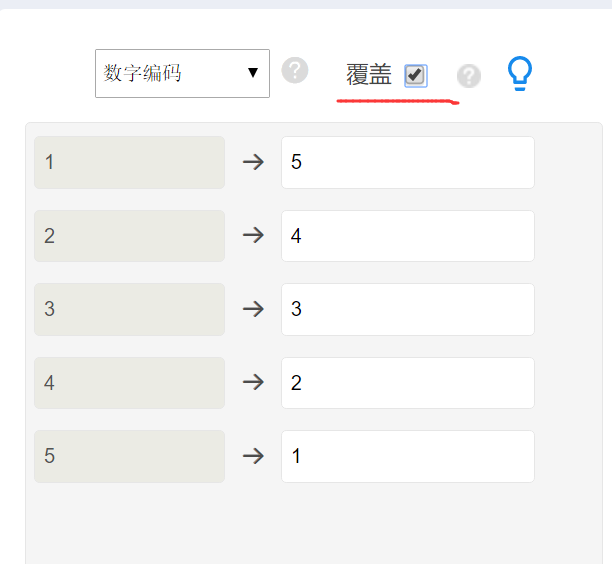
重编码函数
按预设规则把原始取值转换为新取值。
反向计分
常用于 1 到 5 或 1 到 7 量表反向题。
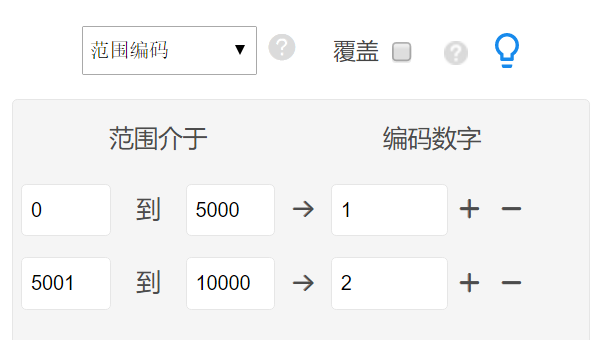
范围编码
落入指定区间的样本赋为同一组别。
3. 数据结构
education 为 1 到 5 的学历编码,reverse_item 为 1 到 5 的反向题,age 可按区间重新分组。
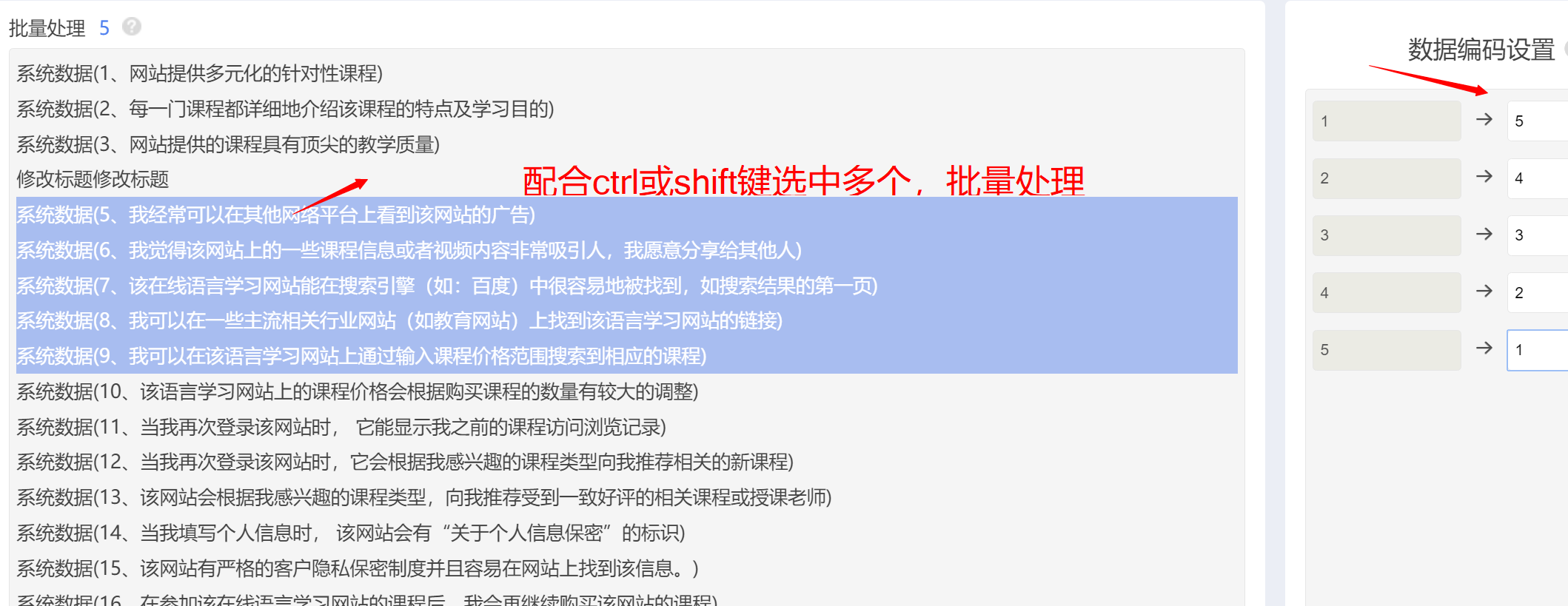
4. 操作步骤与截图
- 上传案例数据
- 进入数据编码
- 选择 education 或 reverse_item
- 设置数字编码或范围编码规则
- 优先生成新变量并检查标签同步
5. 结果表格与核验
| 变量 | 原始值 | 新值 | 新标签 |
|---|---|---|---|
| education | 1,2 | 1 | 本科以下 |
| education | 3 | 2 | 本科 |
| education | 4,5 | 3 | 研究生及以上 |
| reverse_item | 1 | 5 | 反向后高分 |
合并类别和反向计分后应重新检查频数分布。
重点查看编码前后频数是否合理,新变量是否保留样本数,反向题方向是否与正向题一致。
6. 辅助截图

7. 文字分析
数据编码后,原始分类被整理为更适合分析的组别,反向题也被转换为与正向题一致的解释方向。
8. 剖析提醒
覆盖原变量不可逆,正式数据建议先生成新变量并核验,再决定是否替代原字段。